CANoe
脑科学
transformer
特此声明
ACL
资源
xml
rust
web课程与设计
论文
时序选择器
ci/cd
tensorflow
汇编求解一元二次方程的解
fiddler
laravel
项目实战
基础
期权PCR
黄河流域
momentum
2024/4/11 16:08:09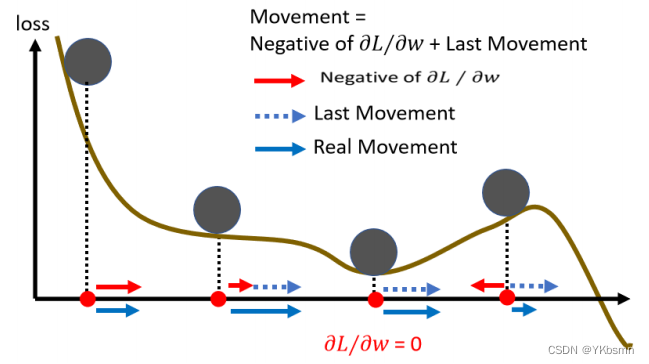
批量Batch and 动量Momentum
1、Batch、epoch、shuffle 首先讲讲Batch,我们实际上在算微分的时候,并不是真的对所有 Data 算出来的 L 作微分,而是把所有的Data分成一个一个的Batch,也有人叫做Mini Batch。每次在更新参数的时候,是拿出一个Batch的数据来计算Lo…
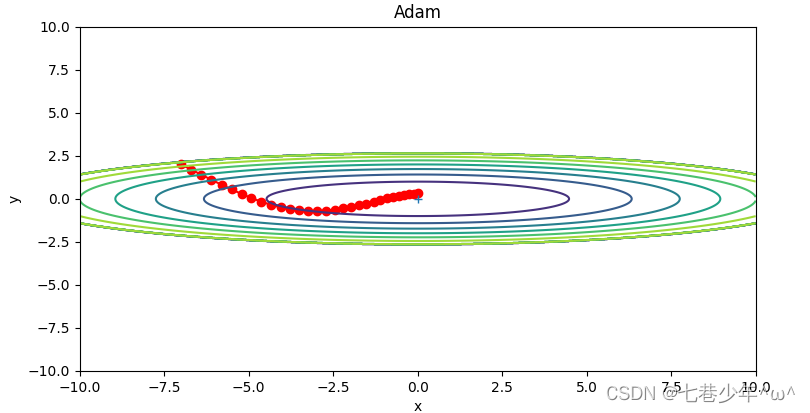
第五章.与学习相关技巧—参数更新的最优化方法(SGD,Momentum,AdaGrad,Adam)
第五章.与学习相关技巧 5.1 参数更新的最优化方法 神经网络学习的目的是找到使损失函数的值尽可能小的参数,这是寻找最优参数的问题,解决这个问题的过程称为最优化。很多深度学习框架都实现了各种最优化方法,比如Lasagne深度学习框架…

深度学习中优化方法——momentum、Nesterov Momentum、AdaGrad、Adadelta、RMSprop、Adam
深度学习中优化方法—momentum、Nesterov Momentum、AdaGrad、Adadelta、RMSprop、Adam—订正说明(2019.6.25):感谢评论留言的同学指正我的一些笔误,现把他们订正过来,订正的主要内容为:
第二节࿱…